解析プログラムの構成
ここでは「猫の手」のスクリプト解析ルーチン analyzer を解説します。
analyzer解説ルーチン
analyzer とはまた芸のないネーミングですが、使う人がカスタマイズして自身のスクリプトシステム名を付けるよう何でもない名前にしています。
解析のシステムですが、命令語を単にコードに置き換えているだけのものである事を前章で触れました。
| NOP | → | 0x00 |
| LET | → | 0x01 |
| ADD | → | 0x02 |
| IF | → | 0x03 |
| JMP | → | 0x04 |
こんな感じです。コードは実際のものとは異なります。
| code = *(バイナリーデータ+i); if( code == 0x00 ){ scr_com_nop(); }else if( code == 0x01 ){ scr_com_let(); }else if( code == 0x02 ){ scr_com_add(); }else if( code == 0x03 ){ scr_com_if(); }else if( code == 0x04 ){ scr_com_jmp(); } i = i + 命令長; ※ソースはイメージです |
| NOP | データ長 4byte |
| LET | データ長 8byte |
| ADD | データ長 8byte |
| IF | データ長 16byte |
| JMP | データ長 8byte |
なのでバイナリーデータの中にその命令の長さが入っています。
解析ルーチンは code を取得して処理、命令長を取得して次の命令に位置を合わせ・・・
という事を繰り返してコードを解釈しています。
その間で引数を同じような方法で取得していますが、引数には格納されている引数の種類などの情報はありません。
従って引数の種類を決める設定ファイル(mlc.ini)の記述と実装されるスクリプト関数(scr_com_〜)で取得しようとする引数の種類は一致してなくてはなりません。
要するに設定では
CHAR(byte, byte, byte,
byte) //引数は1byteデータが4つ
のようなスクリプトを設定したら
実装側で
void scr_com_char(){
a =
get_byte(); //1byteのデータを取得、引数取得ポインタは+1
b =
get_byte(); //1byteのデータを取得、2つ目の引数が取得される
c =
get_byte();
d =
get_byte();
}※ソースはイメージです
のような感じで書く必要があります。これを誤って
void scr_com_char(){
a =
get_dword(); //4byteのデータを取得、引数取得ポインタは+4
b =
get_dword(); //4byteのデータを取得、ここは次の命令コードが入る事になる
c =
get_dword();
d =
get_dword();
}※ソースはイメージです
のように書いてしまうと、最初の a に byte 4つ分の全ての引数を
dwordとして取得してしまい、それ以降は次の命令コードの部分を引数として受け取ってしまいます。
命令長はデータに書いてあるので引数の長さを間違っても次の命令を取り間違うことはない
特に引数の種類を後から変更したりすると
設定ファイルは変更したが取得側は変更しなかった
などで不具合を起こす事があるので注意が必要です。
| 一度、要望により引数の種類をデータに組み込んで、引数の数や種類を自由に記述できる亜種を作成した事がありますが、 結局処理でやるべき事は決まっているので引数を自由に設定できる事の意味はなく、 可変個である事も引数を間違ってもエラーを出さないなどの問題を起こすだけの結果となりました。 |
実際のソースを見てみます。
analyzerフォルダにあるソースが基底解析ルーチンと基本コマンドのソースです。
| sample\analyzer\ | |
| AnalyzerBase.cpp | |
| AnalyzerBase.h | |
| fpc.cpp | |
| fpc.h | |
| register.h | |
解析ルーチンと言っても、バイナリーデータを読んでポインタ渡せば後は勝手にやってくれる〜なんて便利なものではなく
これを継承して自分で解析ルーチンを作成するものです。
analyzer
は共通部分をまとめたものです。
スクリプトの処理の仕方はアプリケーションによって千差万別です。
従ってこれから解説する方法もほんの一例です。これに準じなければならないものではありません。
ですが基本的にはサンプルで提供している形になると思います。
vaiss
<=== AnalyzerBase
拡張スクリプト
基本スクリプト
|
基本部分を同じに別系統のスクリプトを作ってそれぞれに解釈させる事も出来ます
vaiss
<===
AnalyzerBase ※構造が全く違う時に分けた方がよい場合もあるという程度で、通常は共通のスクリプトを使用した方が管理には便利です サンプルでは vaiss2
などの複数個のクラスは用いません |
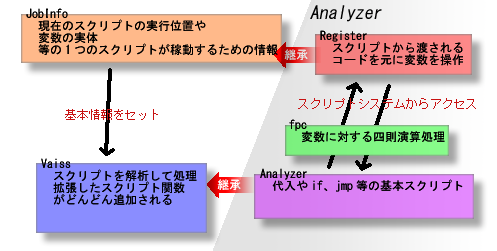
全体の構造図
ここではスクリプトの処理の単位をジョブ(JOB)と呼んでいます。
ジョブの情報を格納したものがJobInfo。複数のジョブを稼動させるには
JobInfo を複数用意します。
スクリプトのどの位置を処理しているのかの情報も JobInfo
が保有しています。
Vaiss側ではそのポインタを保持し、スクリプトを処理しています。
複数のジョブを作成してもVaissの実体が1つになる構造にしているためです。
JobInfo は Analyzer の持つ Register を継承して作っているので JobInfo内の変数の実体をスクリプトから操作できるのです。
変数は全てインデックスで管理されるのでアプリケーション側からはスクリプトで宣言した変数名を識別する事は出来ません。
スクリプトで宣言した変数はスクリプト中だけで使用できます。
しかし、アプリケーションとで値のやりとりをしたい場合もあります。
そのために変数宣言時に決まったインデックスを与える機能があります。
DISP_W,
DISP_H
という変数にアプリケーションから画面サイズを与え、スクリプトから画面サイズを得る
RANDOM
という変数にアプリケーションから乱数値を与え、スクリプトから取得
または逆にスクリプトで設定した値をアプリケーションで取得
といった使い方が出来ます。
その場合、変数インデックス 0x0000 〜 0x00ff までを固定変数、0x0100 以降を自由変数、というように管理します。
章締
「猫の手」ではスクリプトで変数を宣言する事を推奨していません。
スクリプトはプログラマーでない人間に作業ができる事に意味があると考えているからです。
ツールの構造上、スクリプトから宣言させてより言語らしく動作させる事が可能だから一応対応しているだけで
スクリプト作業の安全性からはスクリプトからしか扱えない変数や使用数の読めない手段は無意味だと考えています。
スクリプトから宣言させなくとも予めフリーに使っても良い固定変数を用意しておけば事が足りるからです。
(固定変数に自由な名前を付けたい場合、define
を使えばよい)
スクリプトにどの程度の自由度を与えるかについてはスクリプトで何をさせるかに依存するので
一概にどこまでの機能をあてるかの境界線はありませんが
この「猫の手」開発者的に
スクリプトで自由に変数宣言をさせるのはスクリプトの機能を逸脱したもので、それなら初めからプログラムを組んだほうが早い
という線引きをしています。
次章では実際にプログラムソースを見ながら解説していきます。